Spring Boot结合Mybatis与WebMagic爬取校内电影网电影信息并保存到MySQL数据库
写在前面
昨天的那篇文章大致分析了一下WebMagic的执行流程,对爬虫执行的流程有了初步的了解,那么今天的重点就是研究如何将爬取到的信息保存到自己的数据库当中。将数据保存到数据库实际上有很多种方法,比如说直接使用原生的方式连接数据库并保存数据或者使用现有的一些框架来帮助我们操作数据库,在这里,我选择的是后者,这一次的爬取我决定使用现在最流行的Spring Boot框架和Mybatis框架来进行,这里有一个问题需要指出的就是,虽然看起来使用这两个框架来处理这一点事情好像有点大材小用,但是这能够帮助我们学习这两个框架,而不仅仅是爬取数据并保存到数据库。OK,废话也说的差不多了,进入主题。
创建Spring Boot项目
在开始之前,我们需要先创建Spring Boot项目,并且使用Maven作为项目的构建工具。开发环境我这里选择的是IDEA,如果你对IDEA不太熟悉的话,你也可以使用eclipse来创建项目。在File菜单里选择New > Project,选择Spring Initializr,然后选择SDK的版本以及Initializr Service URL,完了之后下一步
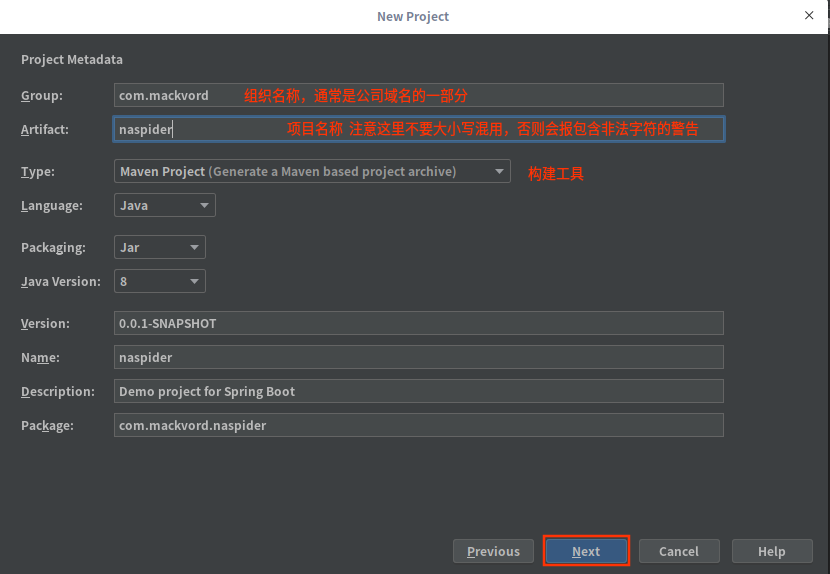
接下来是配置项目的元数据,包括组织名称、项目名称、构建工具、使用的语言等等,配置完后选择下一步
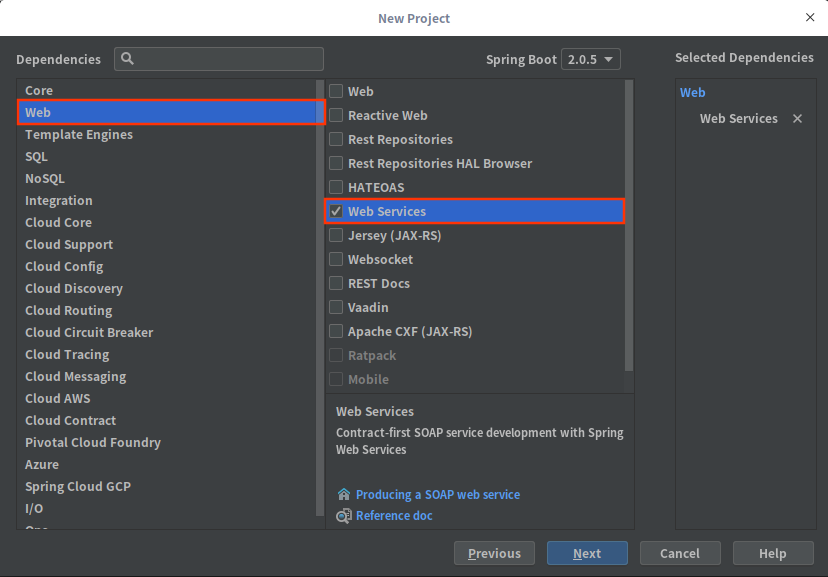
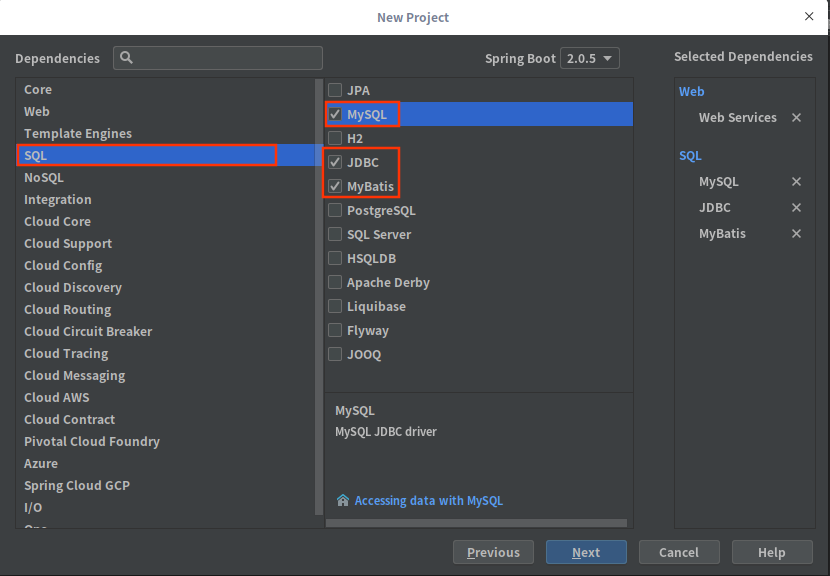
接下来就是选择需要的依赖了,由于我们需要的功能并不多,所以依赖部分只选择web当中的Web Service以及SQL当中的MySQL、JDBC以及MyBatis,之后选择下一步
到这里就到了最后一步了,这里主要是配置项目存放的路径,配置完了点击Finish即可
最后项目的目录结构如下
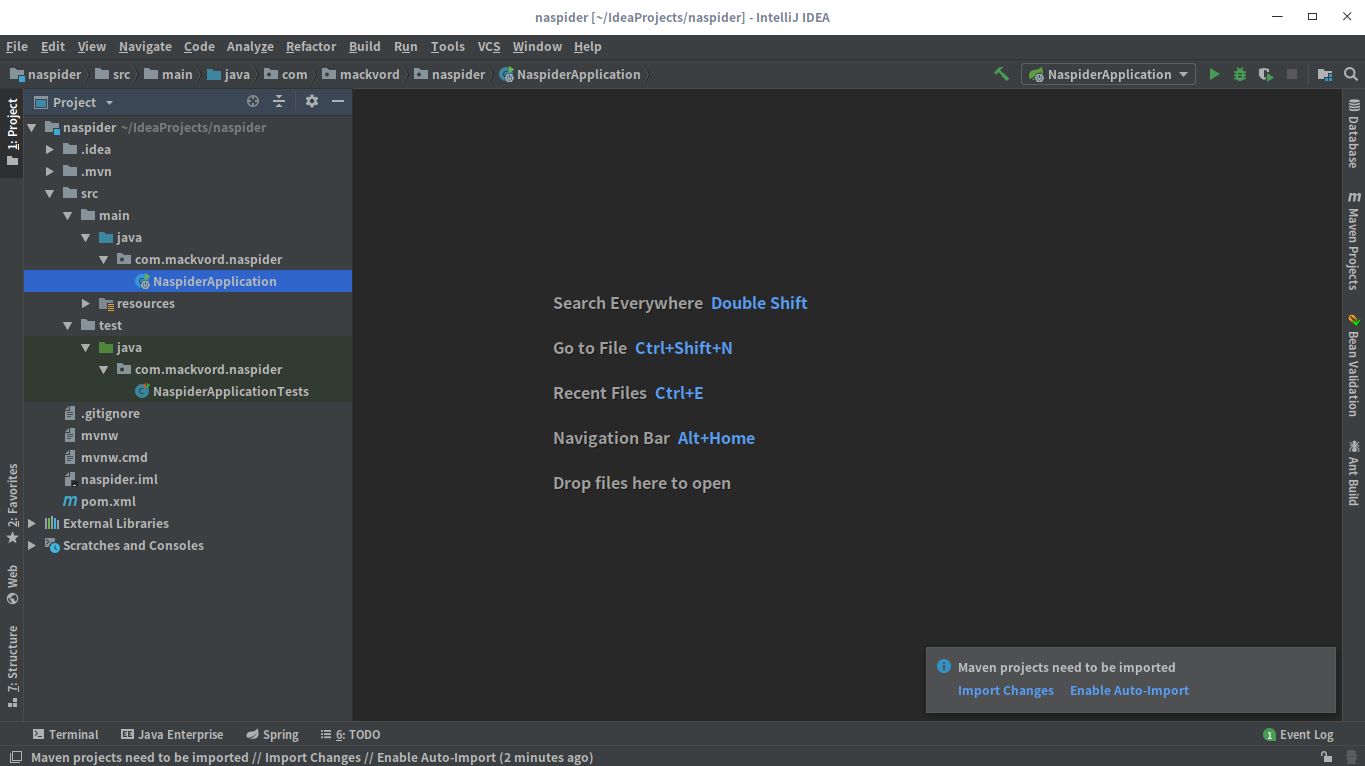
配置pom.xml
项目创建好了之后,在导入依赖之前还需要编辑pom.xml文件,引入WebMagic的依赖
1 | <!-- webmagic核心依赖 --> |
完整的pom.xml文件如下:
1 | <?xml version="1.0" encoding="UTF-8"?> |
编辑完pom文件后,点击右下角的弹窗中的自动导入或者打开右侧的Maven Projects面板导入项目的依赖。
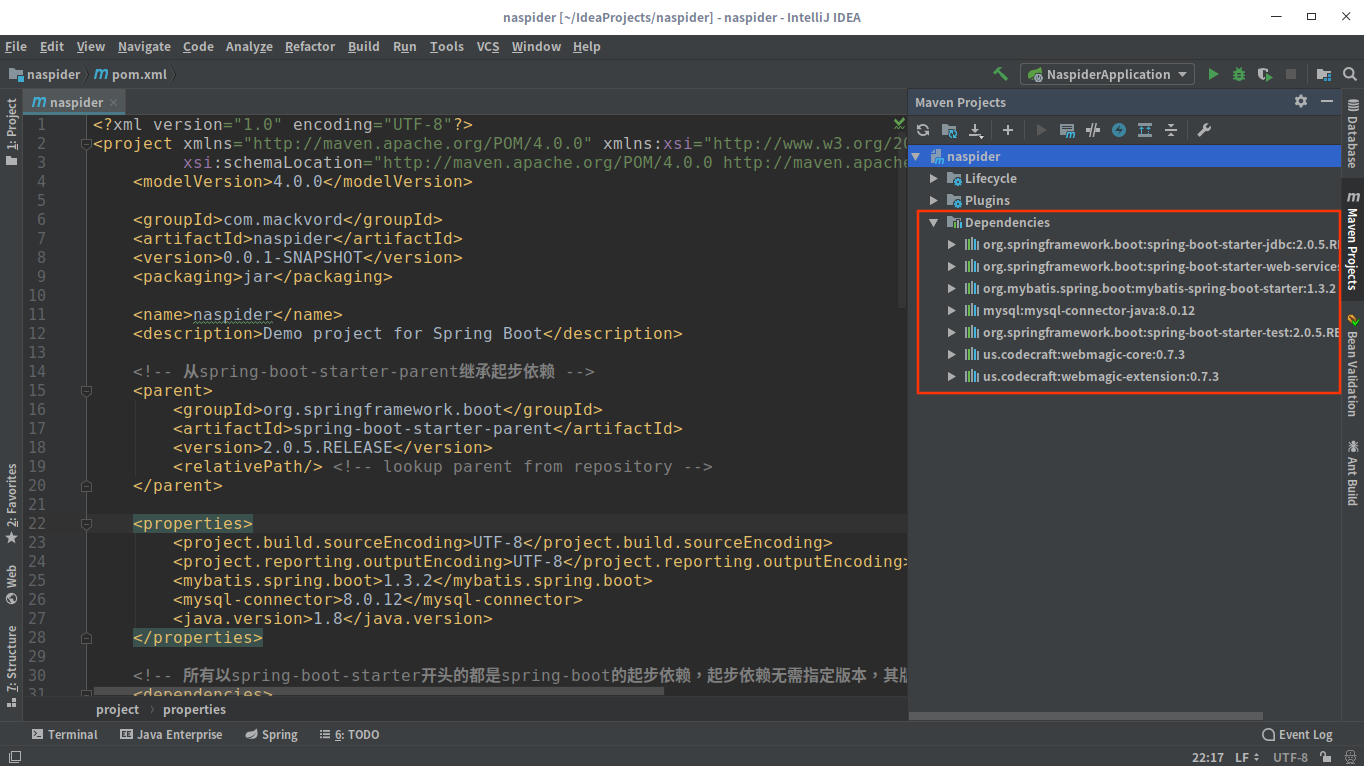
完善项目结构
引入依赖之后,我们需要完善一下项目的结构,新建几个目录,最终的项目结构如下:
配置application.yml
application.yml文件主要用来配置数据库的连接信息以及mybatis的相关配置,实际上这些配置也可以在application.properties文件中配置,两者是等价的,但是我个人更倾向与使用application.yml文件来进行配置,这样更简洁一些。需要配置的信息如下:
1 | server: |
创建数据表
数据表的创建的可以使用命令或者使用一些图形化的数据库管理工具来进行,为了方便,我这里选择使用Navicat这款工具来创建数据表,这款工具是要收费的,但是可以免费试用14天。表字段的设计与你自己想要爬取的信息相对应,我这里主要是爬取视频的名称、分类、播放地址以及封面图片的地址,所以表的设计如下
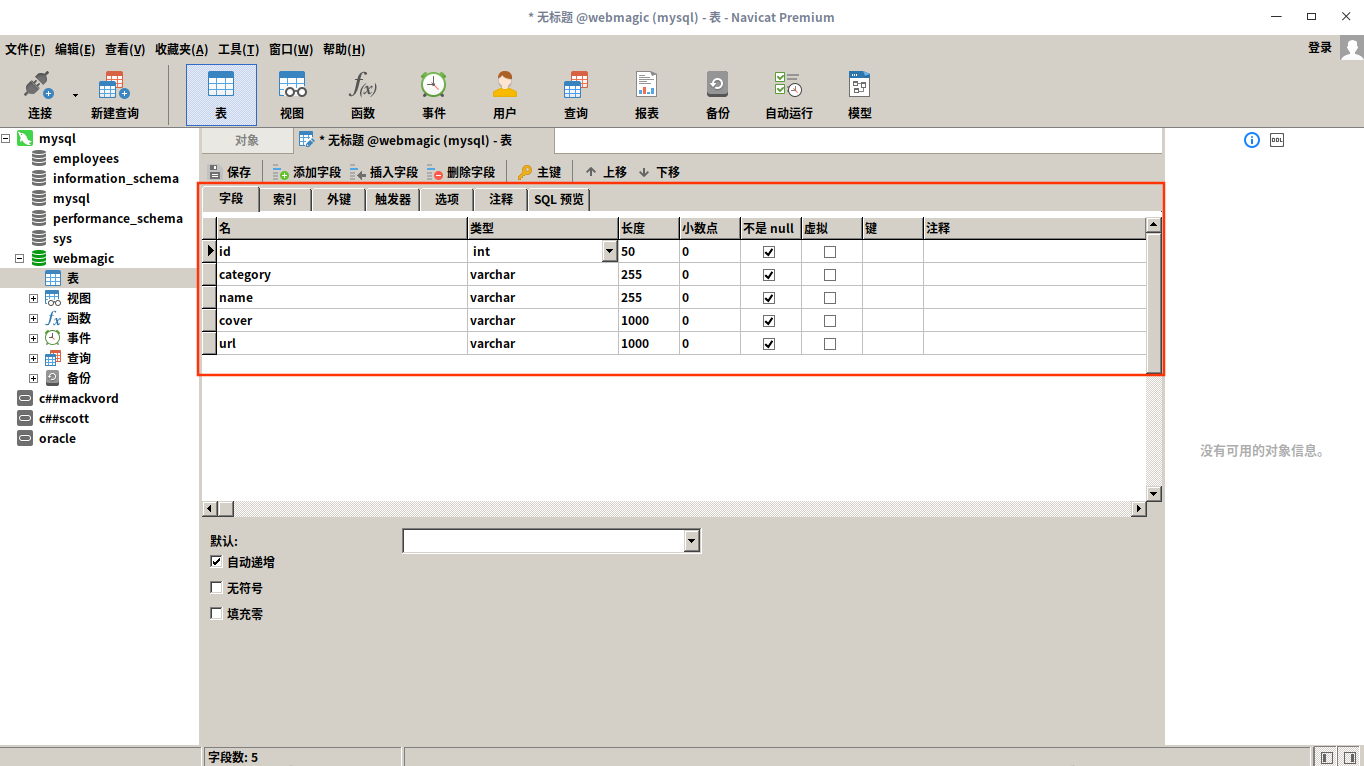
创建实体类
在model包(关于这个包的命名也可以命名为bean或者domain,这里我居然纠结了好久~~~![]() )下面创建与数据表对应的实体类Video,代码如下:
)下面创建与数据表对应的实体类Video,代码如下:
1 | package com.mackvord.naspider.model; |
创建VideoDao
VideoDao是一个接口,在这个接口当中定义操作数据库的方法,因为只涉及到保存数据,所以这里只定义了一个方法:
1 | package com.mackvord.naspider.dao; |
创建VideoDao.xml
VideoDao.xml这个命名好像不太规范,关于命名这一块一直都很纠结,不过并不影响程序的执行,所以暂时就先这样命名![]() 。
。VideoDao.xml文件的内容如下:
1 | <?xml version="1.0" encoding="UTF-8" ?> |
其中insert元素中的id属性需要接口中的方法名相对应,当然如果你比较熟悉MyBatis这些配置一眼就能看懂。
创建MysqlPipeline类
在pipeline包下创建MysqlPipeline类,其实这个类你可以理解为Service层的一个类,它的作用就是帮助我们去调用DAO层的方法,这个类的代码也很简单:
1 | package com.mackvord.naspider.pipeline; |
实现PageProcessor接口
这一部分就是爬虫的核心了,所有与爬虫相关的抽取逻辑,包括对象的封装都在这一部分完成。在processor包下面创建NaProcessor类,代码如下:
1 | package com.mackvord.naspider.processer; |
额~~~代码看起来有点乱,我简单解释一下,最开始我定义了两个正则和一个起始的URL地址(这个链接的长度我真的是不想吐槽了),起始的URL地址不用多说就是我们爬虫的开始爬数据的地址,而这两个正则分别是匹配页面当中的导航栏的最小分类链接和此分类当中的分页链接,这么说好像不太明白,我直接上图吧,看下面的图
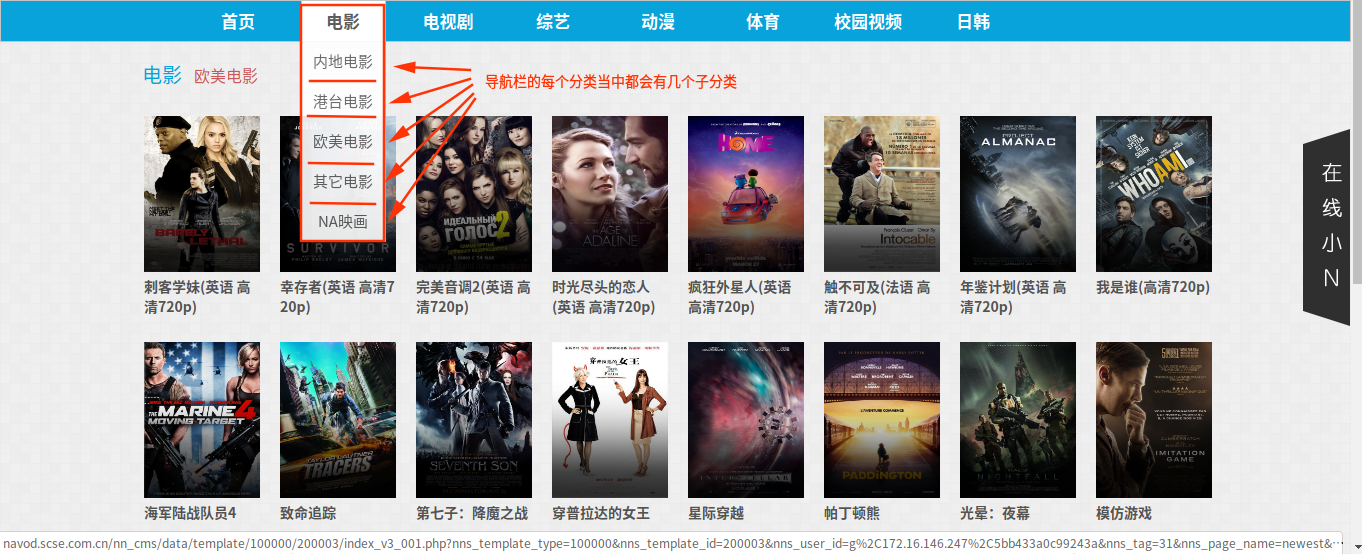
可以看到,在导航栏当中的每个分类下面,都会有几个子分类,我们再来看页面的源码
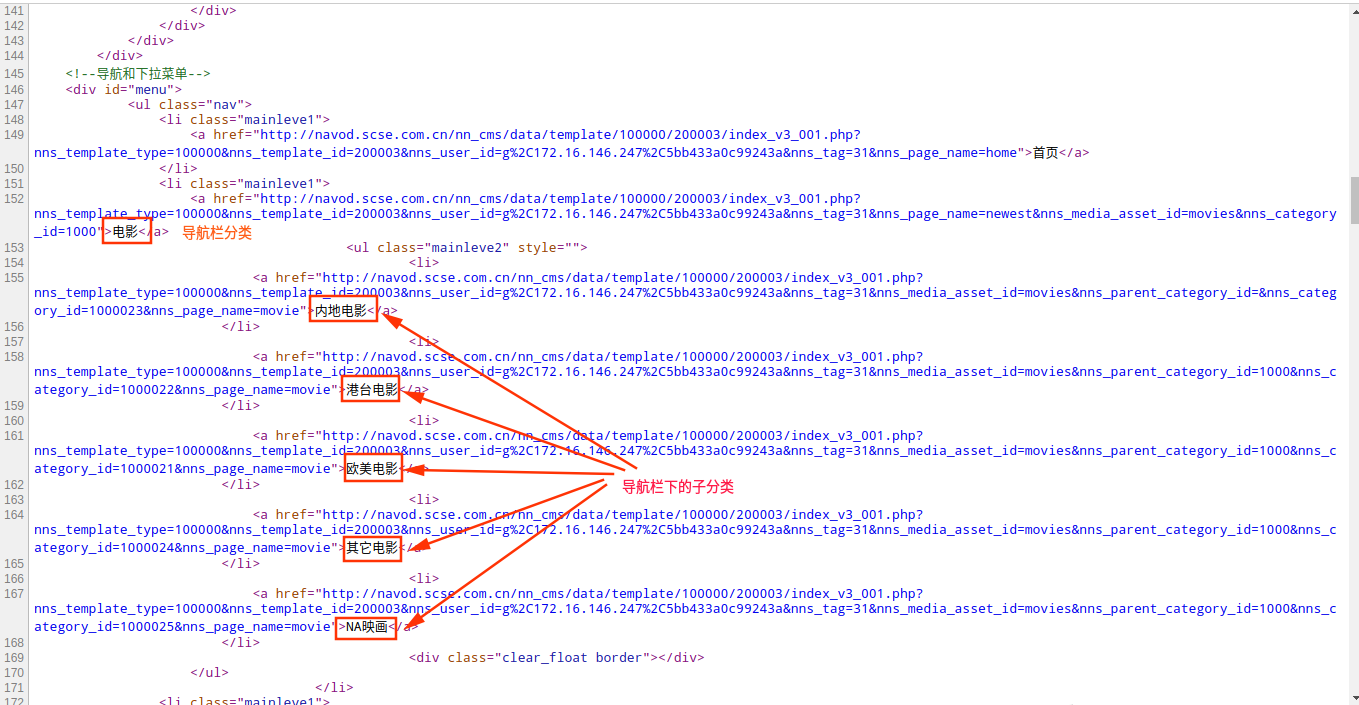
除了电影分类,其他分类都是相似的,每一个子分类的对应的链接都具有某种规律或者说是符合某种正则的,而每一个子分类页面下可能会有分页显示,其中每一页最多显示24部电影或者视频的相关信息。

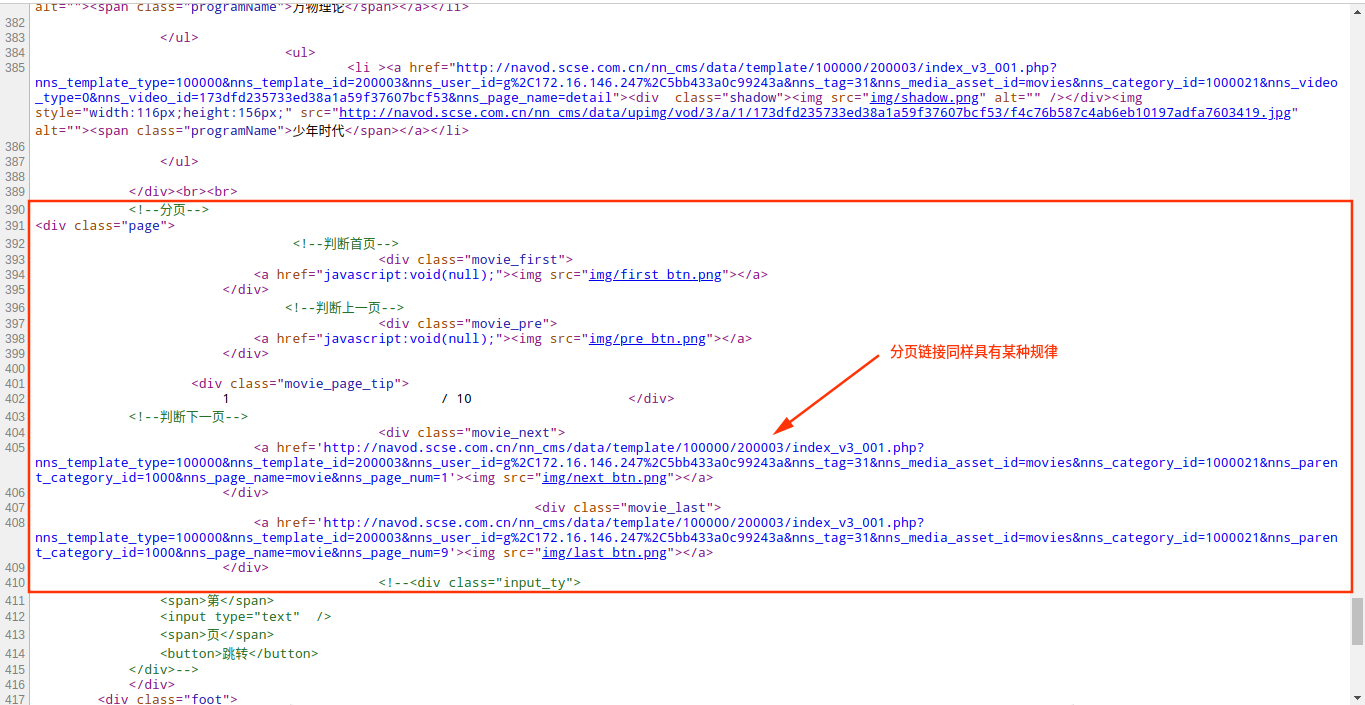
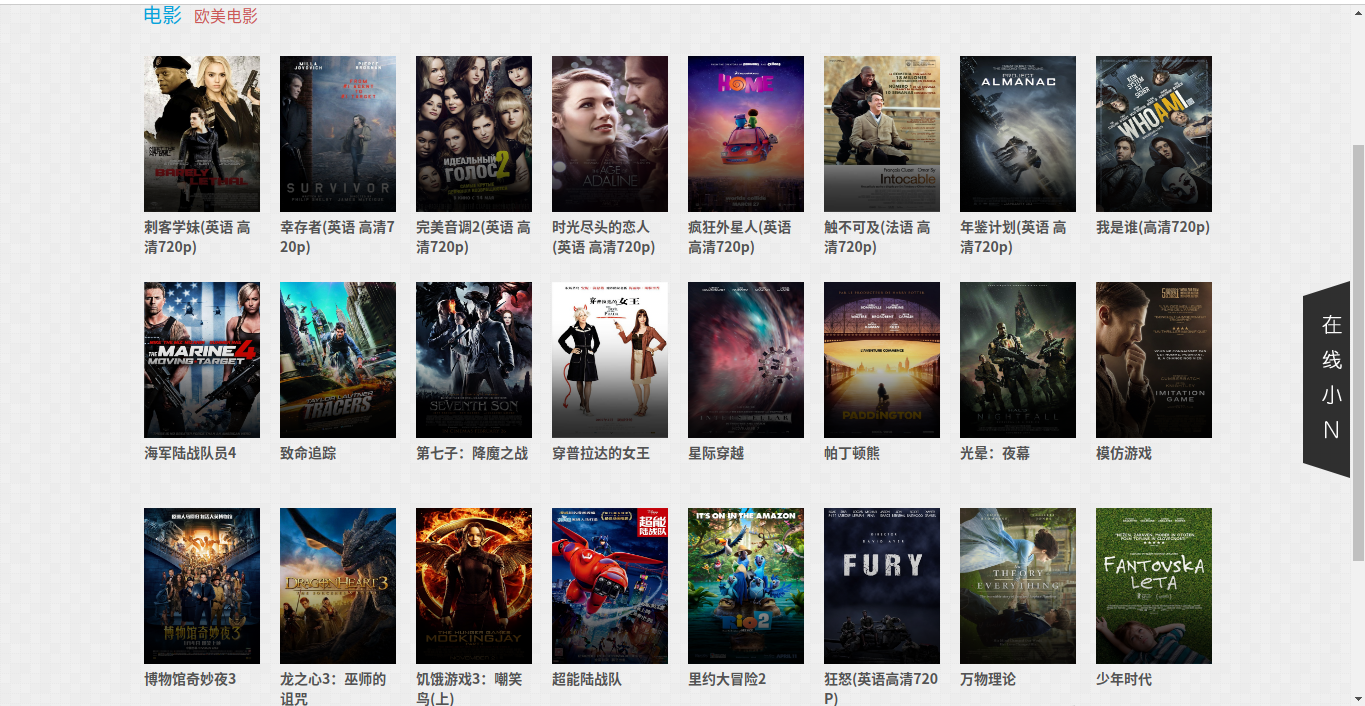
分析到这里,其实抽取链接的部分已经搞定了,接下来就是抽取我们想要的信息了,同样还是查看页面的源码,分析不同分类的页面的显示规律
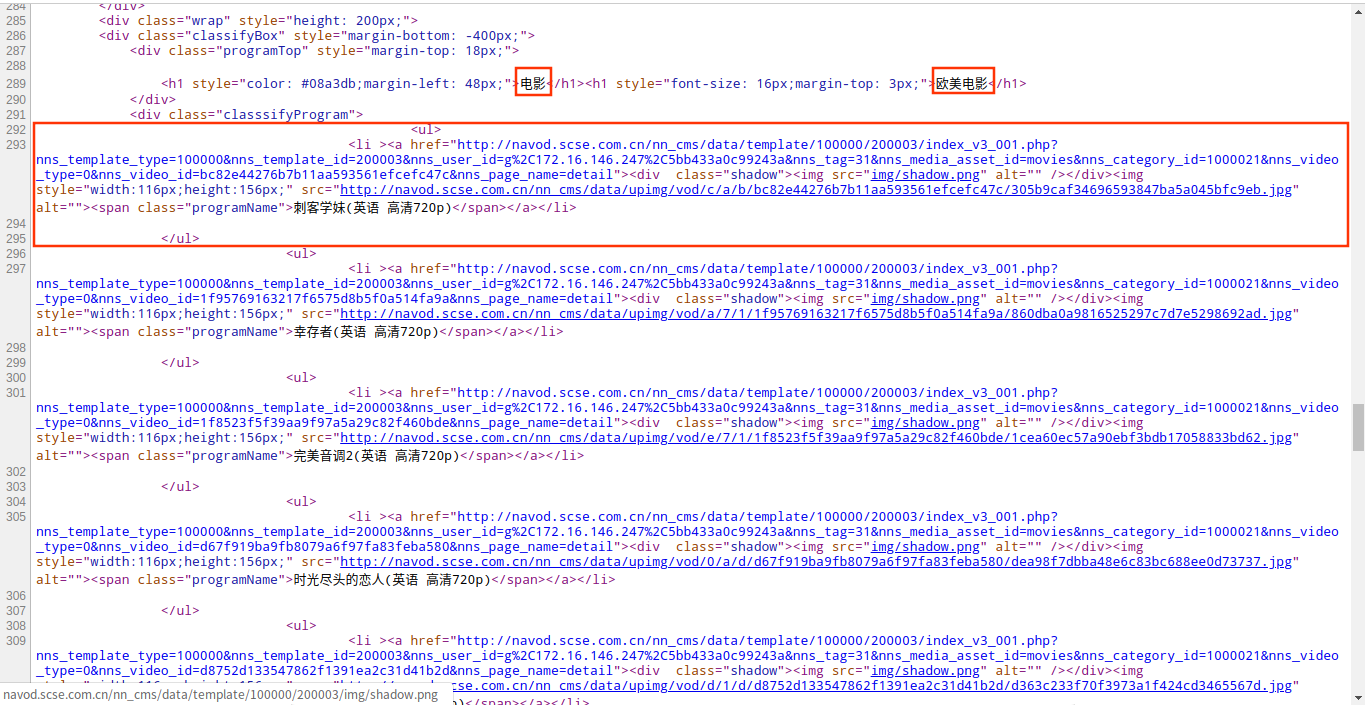
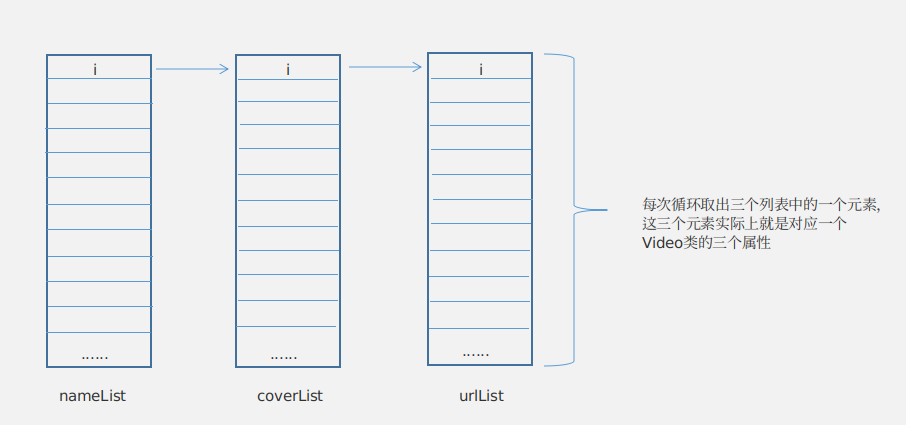
通过查看页面源码可以发现,每个页面都会显示页面分类以及电影的列表信息,包括名称、封面海报以及播放地址,而这些就是我们要抽取的信息,完整的代码上面已经贴出了,这里就不再写了,其中的分类,我抽取的是导航栏中的分类而不是子分类。爬虫每一次爬取页面都会调用NaProcessor类中的process方法,这个方法会将页面当中我们需要的信息爬取下来,包括一个分类和三个list集合,这三个list集合分别存放的是电影名称、封面地址、播放地址,所以后面我用了一个for循环封装Video对象并调用MysqlPipeline类中的save()方法将数据保存到数据库。这里可能你会疑惑如何控制for循环的循环条件?怎么才能够确保封装对象的时候其名称、封面以及播放地址是对应的?其实你仔细想想就会发现,这三个list集合的长度是一样的,因为每个页面当中的电影列表中的每一部电影都会包含名称、封面、播放地址这三部分的信息,所以循环条件部分就解决了,就是任意一个list集合的长度。而关于保证循环封装对象的正确性,看下面的图你就会明白了(画图水平有限,别吐槽~~~)
创建controller
到这里实际上主要的部分已经完成了,创建controller只是为了通过访问web地址来启动爬虫。这里在controller包下创建一个NaSpiderController类,代码如下:
1 | package com.mackvord.naspider.controller; |
测试
最后一部分就是测试爬取数据了,在IDEA中运行NaspiderApplication类的main方法启动项目,整个过程我录了一个视频
结束语
从搭建项目,到爬取数据、保存数据库到数据库整个过程到这里就已经结束了,在这个过程中,实现PageProcessor接口部分是最重要的,在这一部分当中需要自己取分析页面的结构,抽取需要的爬取的链接和信息,并且还要封装对象。这一次主要是爬取了学校内网的电影信息,下一次的有时间的话,再爬取一些其他网站的信息。如果你也对爬虫感兴趣,欢迎给我留言,一起交流学习!源码我已经放到了github上,地址: https://github.com/mackvord/NaSpider


