爬取拉钩网热门城市,包括北京、上海、广州、深圳、杭州、成都、武汉、南京3600条Java开发工程师招聘信息
写在前面
上一篇文章介绍了如何爬取学校内网的电影信息,这一篇文章来讲一下爬取招聘信息,恰好最近我也需要找实习,所以就来扒一扒那些互联网公司对Java开发工程师这一岗位都有哪些要求,薪资待遇如何。这一次爬取的主要是一些热门城市,例如北上广深等等,数据一共爬了3600条。
分析页面
首先页面分析肯定是玩爬虫的前提条件,如何发现链接、如何抽取有效信息,这些都是需要事先解决的问题,只有找到页面的规律才能进行下一步的操作。以拉勾网为例,其页面的数据并不是由服务端渲染完成后再返回给前端的,而是通过返回json数据,由前端进行渲染展示。所以这就带来了一个问题,之前那种直接抓取页面链接,抽取信息的方法已经无法完成抓取任务了。接下来打开google浏览器的调试工具,我们访问Java相关的招聘页面,并限定工作地点为北京,首先先看Headers部分的信息,其中Response Headers(响应头)和Query String Parameters(查询的字符串参数)这两个部分的信息可不用理会,我们重点来看General、Request Headers和From Data这是三个部分,General包含了请求的URL地址以及请求的方式,划线的部分是转码后的中文北京,不同的城市这一部分是不同的。
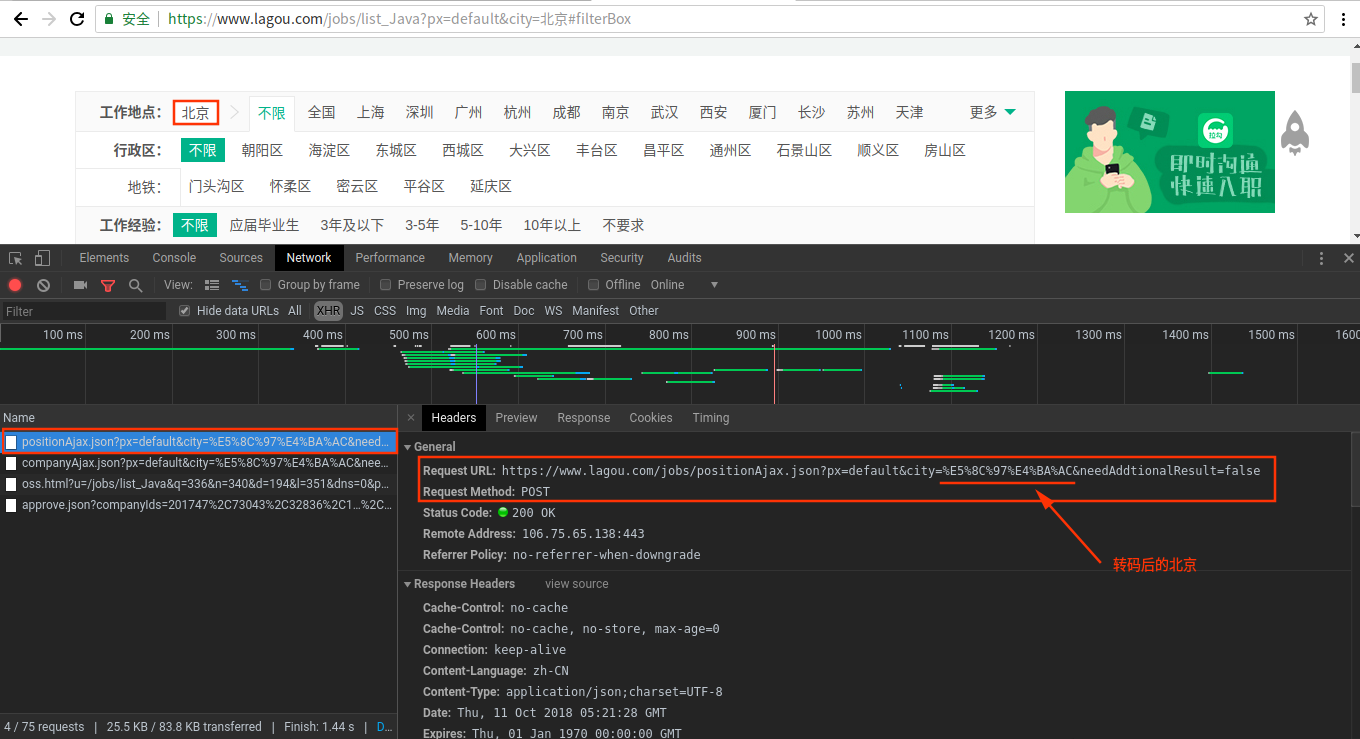
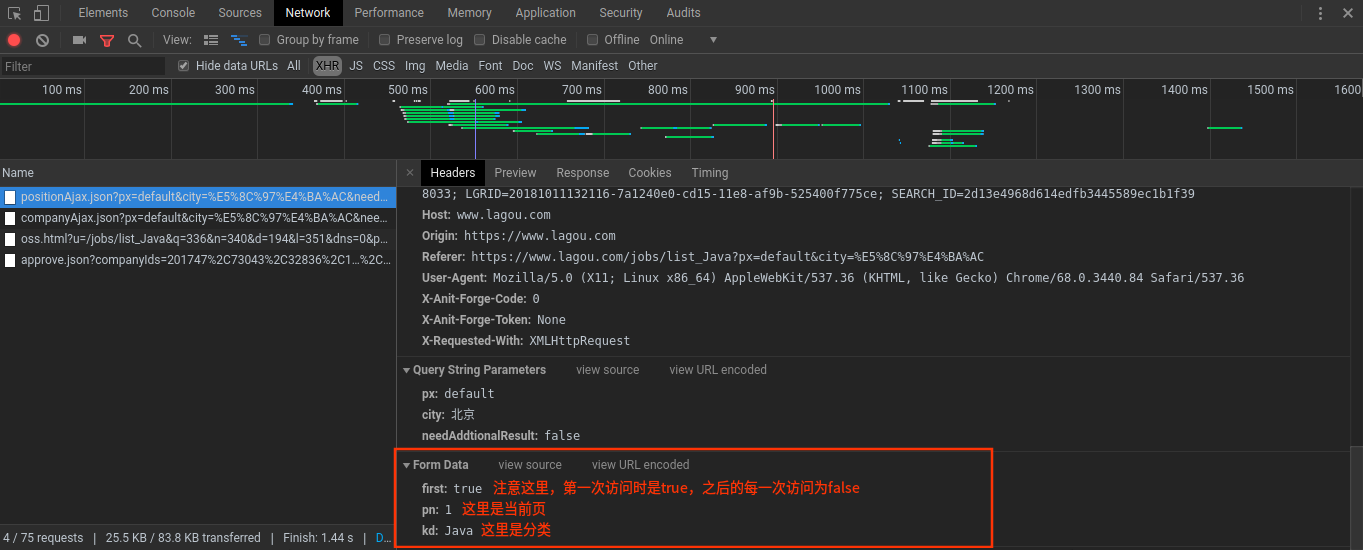
Request Headers主要是包含一些请求头信息,这一部分变化不大,主要是From Data中会有一些变化,如果是第一页,first的值为true
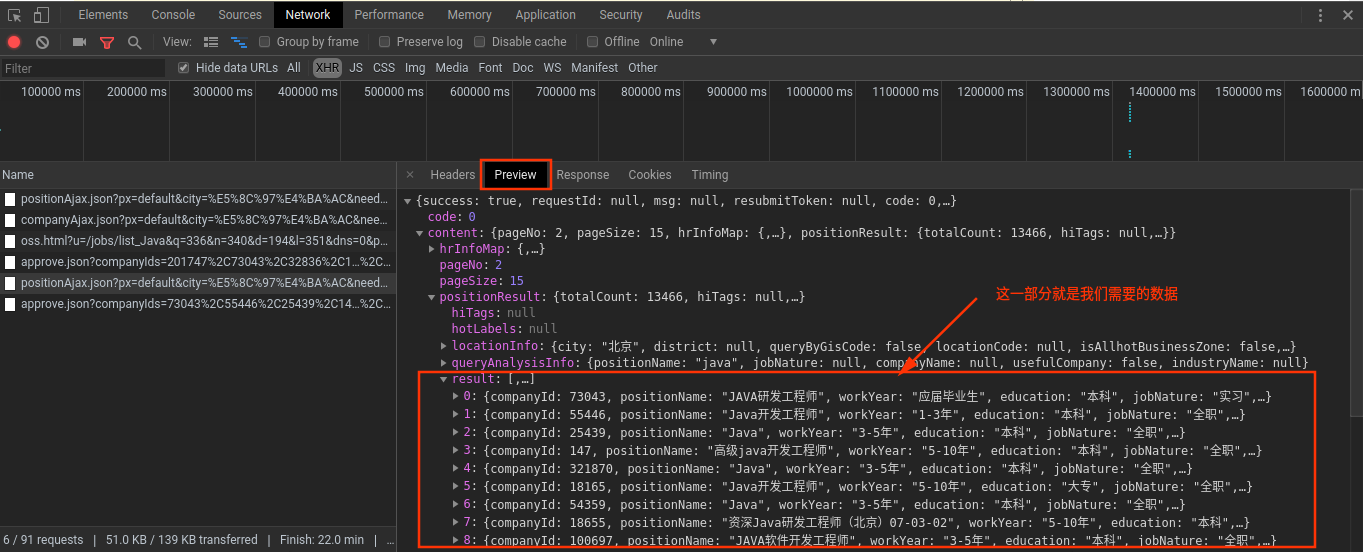
然后就是数据部分,服务端返回的json数据在Preview中的content可以找到,如下图:
设置站点信息
这里主要是设置请求头信息,其中的键值根据调试工具显示的来进行添加即可
1 | /** |
构造链接
由于服务器返回的是json数据,所以我门必须手动构造链接,模拟请求,代码如下:
1 | public void processHotCity(Page page) { |
封装对象
抽取服务器返回的json数据中自己需要的信息,并封装成对象,保存到数据库
1 | /** |
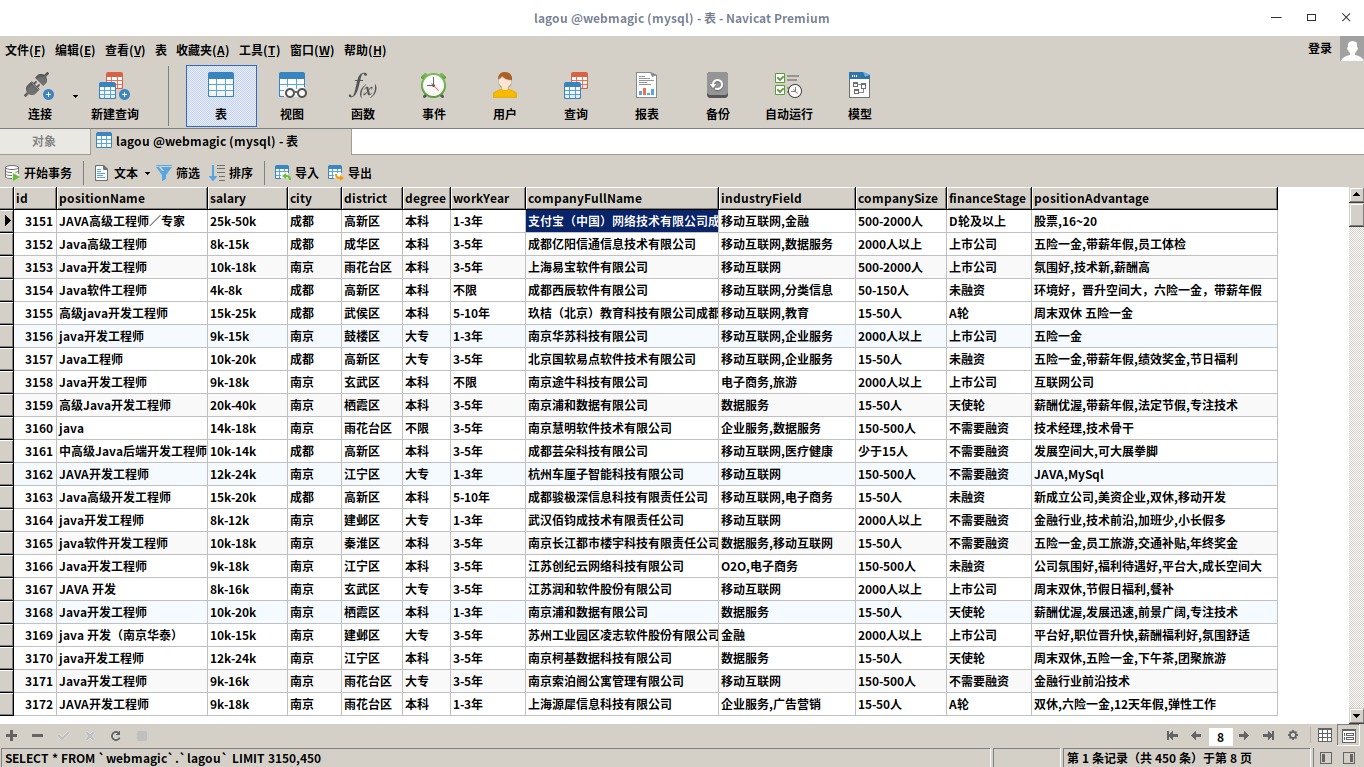
爬取的结果
一共爬取到3600条数据
数据的可视化
数据的可视化使用了百度的开源JavaScript可视化库echarts,由于在Markdown中直接引入js没有办法渲染,所以这里使用一个插件: hexo-tag-echarts来进行可视化,这个插件有两个版本,一个是hexo-tag-echarts,另一个是hexo-tag-echarts3,前者是原作者的作品,但已经不再维护了,所以我用的是hexo-tag-echarts3,具体的用法可以参考:http://zhoulvjun.github.io/2016/02/07/hexo-tag-echarts/
从公司的融资情况来看,不需要融资的公司提供的岗位数量会多一些,大概占到三分之一,其余融资阶段,包括未融资的公司提供的岗位数量差别并不算太大。
从学历与职位数量的关系图来看,在这3600个招聘岗位中,要求本科学历的岗位数量达到了2795个,占了大部分,看来本科学历在企业招聘中还是有一定优势的。
从上面工作经验与岗位数量的关系图来看,似乎大部分的公司提供的职位,都需要求职者有3-5年工作经验,这个比例占到了57.25%,而1-3年工作经验以及5-10年工作经验的比例加起来也达到了36.78%,那么对于像我这样的应届毕业生来说,就只能躲在角落里瑟瑟发抖吗?那倒也未必,毕竟这只是像北上广深等一些热门城市的招聘岗位,而且仅限于拉勾网,数据样本的数量也有限,只有3600条数据,所以数据还是欠缺说服力(自我安慰![]() )。看来应届毕业生在拉钩找工作不太合适,合适的岗位数量太少。
)。看来应届毕业生在拉钩找工作不太合适,合适的岗位数量太少。
Reference Paper
结束语
这里有一点要注意的就是,以上爬取的城市,其职位列表都是30页的,所以我注释了一部分分页不足30页的城市,如果要构造这些城市的职位列表链接,有点麻烦,暂时还没想到比较好的办法,而且以上构造链接的代码用到了两个for循环,显然性能上会有一些问题,如果各位看官有什么比较好见解,欢迎留言告诉我,共同交流!


