使用webmagic框架爬取学校内网的电影资源信息
写在前面
说到爬虫,估计很多人的第一反应就是Python的Scrapy框架,确实,Scrapy框架可能是当下最为流行的爬虫框架了,这一点从github上Star数量就可以看出,但是由于我自己对于Python并不太熟悉,所以没能够体验这个框架的魅力,所以这篇文章的主角是另一个用java编写爬虫框架WebMagic,WebMagic框架是由国人黄亿华先生开发。
关于架构
WebMagic的总体架构非常简单,主要由四个组件构成,分别是: Downloader、PageProcessor、Scheduler以及Pipeline,这四个组件对应了爬虫生命周期中的下载、处理、管理和持久化等功能。官方给出的结构图如下:
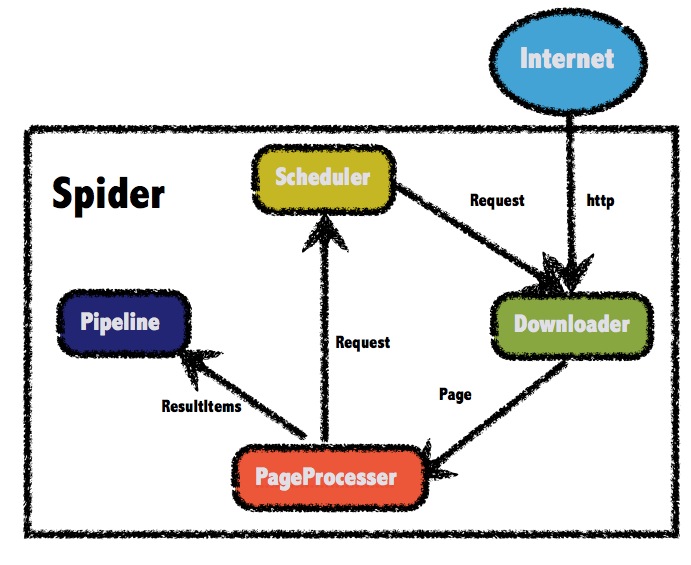
入门程序
入门级的程序非常简单,只需要我们定制爬虫的核心借口PageProcessor的实现即可,当然中间可能需要了解一些关于xpath以及css选择器抽取链接的知识。这一部分,你也可以参考WebMagic中文文档
创建maven项目
使用IDEA来创建Maven项目,项目的创建过程很简单,所以过程就不截图了,最终的结构大致如下:
配置依赖
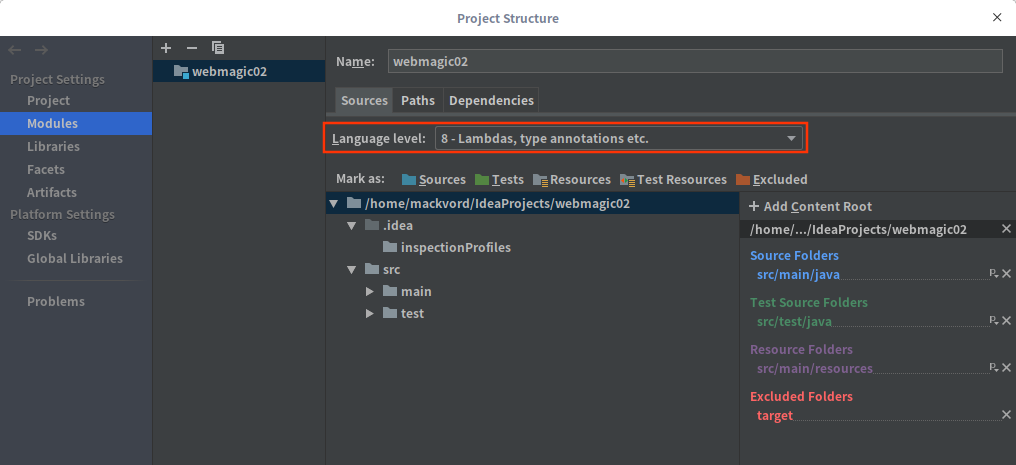
依赖部分,由于是入门程序,所以仅配置了webmagic-core以及webmagic-extension两个必须的依赖,而maven-compiler-plugin是为了避免IDEA在刷新pom文件后language-level重置为jdk5的问题,IDEA默认的language-level为jdk5,如果不修改,会导致代码中的注解或者其他的一些特性无法识别,所以我这里将其修改为jdk8
完整的pom文件如下:
1 | <?xml version="1.0" encoding="UTF-8"?> |
配置日志
如果你使用官方的demo来实现一个简单的爬虫的时候,你会发现,会报一个错误:
1 | Picked up _JAVA_OPTIONS: -Dawt.useSystemAAFontSettings=gasp |
这是因为没有配置日志所导致的,所以需要把log4j.properties文件配置好,放到resources目录下
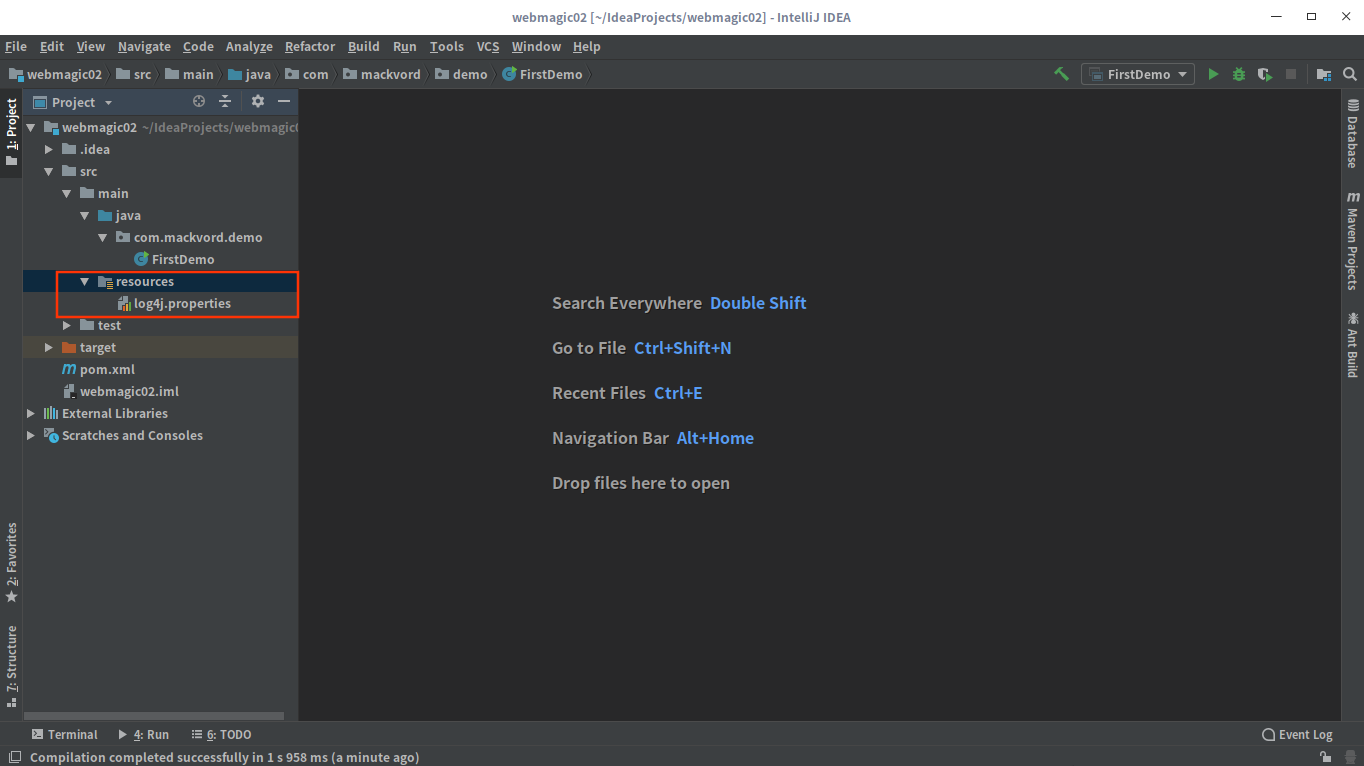
具体的配置如下
1 | log4j.rootLogger=WARN, stdout |
如果你使用官方提供的入门案例并且是使用maven来构建项目的话,可能会碰到javax.net.ssl.SSLException: Received fatal alert: protocol_version这个错误,具体的解决方案请参考https://segmentfault.com/a/1190000014202558
抽取链接和信息
这一部分就是通过分析页面的结构,提取我们需要的信息,通过观察发现,需要抽取的链接存在一定的规律,但是链接非常地长,如果用正则可能比较麻烦,所以这里我选择使用css选择器进行链接抽取
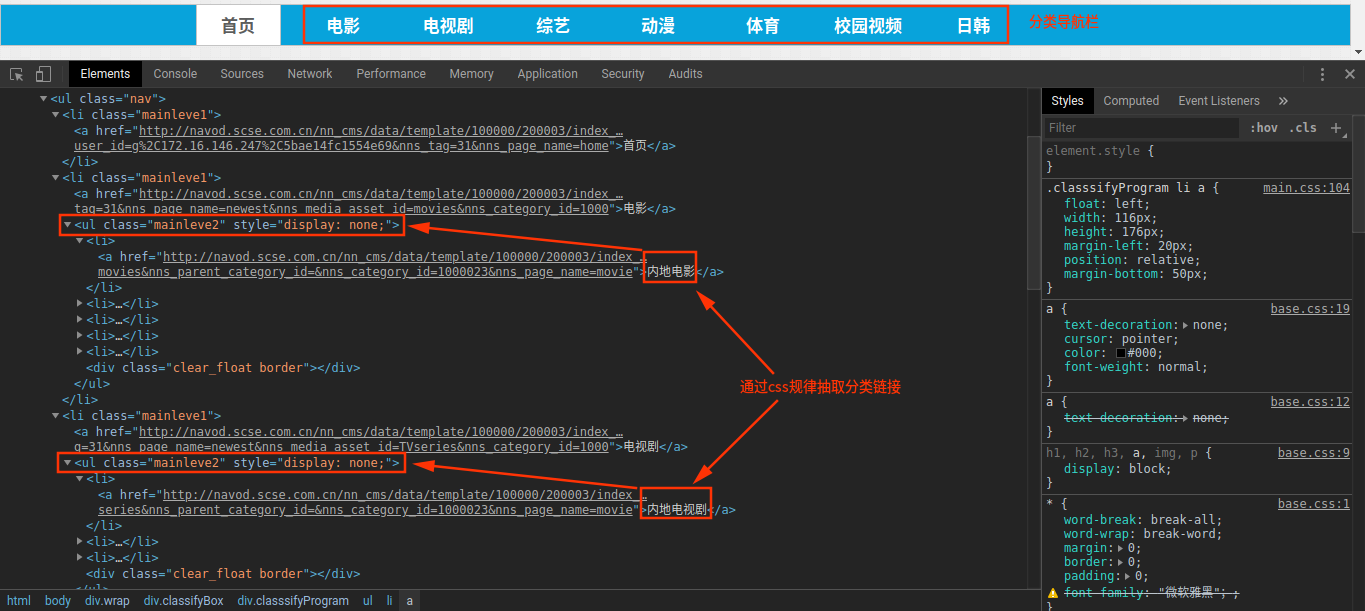
经过分析,直接使用以下代码就能获取所有分类的链接
1 | List<String> links = page.getHtml().css("ul.mainleve2").links().all(); |
获取链接之后就是抽取我们需要的信息了,通过查看源代码发现,所有的电影或者视频都是使用以下的html代码包裹
1 | <span class="programName">xxxx</span></a></li> |

所以信息的抽取的代码如下:
1 | // 抽取分类 |
定制process核心接口实现
PageProcessor是定制爬虫的核心接口,在process()方法中编写抽取的逻辑,具体如下:
1 |
|
可以发现,相比于官方提供的demo,我仅仅只是修改的链接的抽取以及想要获取的信息,完整的代码如下:
1 | package com.mackvord.demo; |
效果
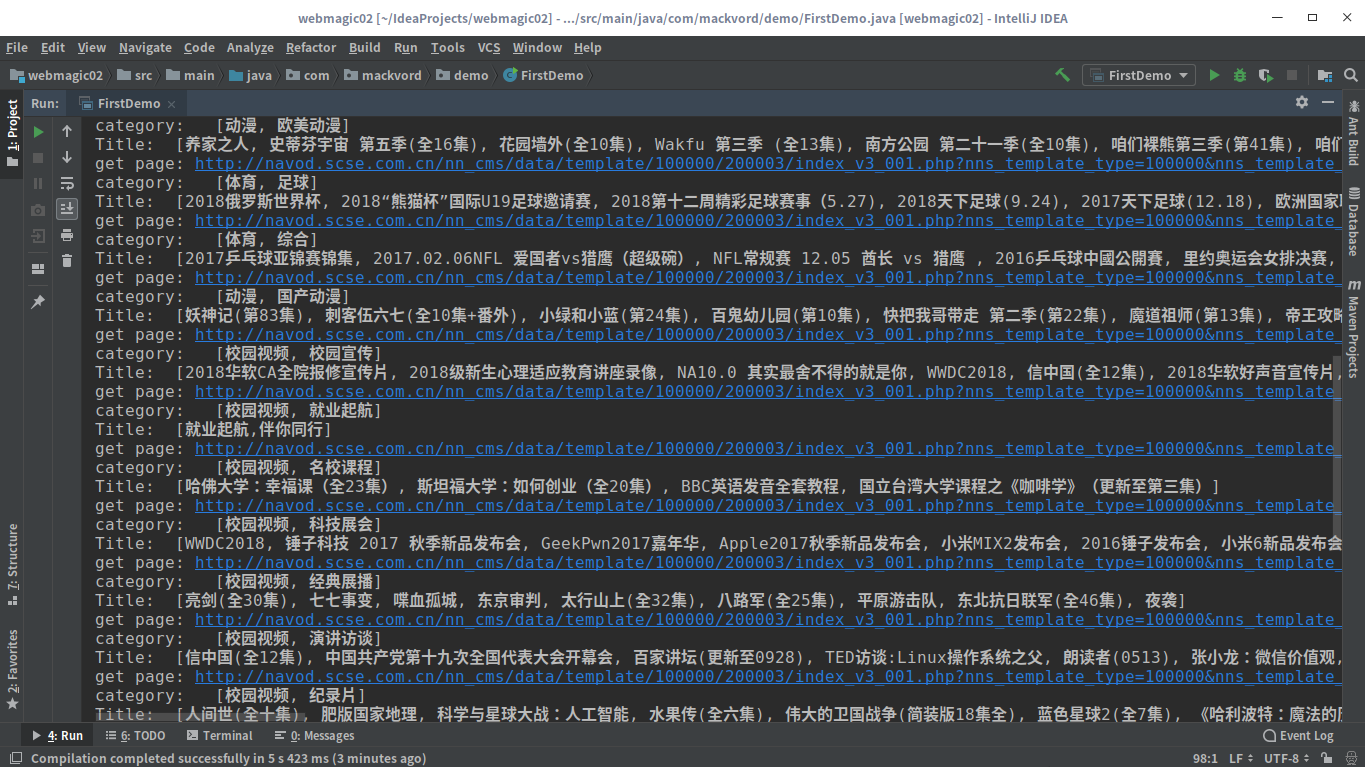
结语
这仅仅是使用webmagic框架的入门级程序,还有相当多可以改进的地方,现在我们爬到的数据都是直接在控制台打印出来,并没有对数据进行进一步的处理,比如说将数据保存到数据库,数据分析等等,所以接下来就是研究怎么将数据保存到数据库、以及进行数据分析。

