对正则表达式的一些语法的理解以及回顾
简介
正则表达式(regular expression)是一种用于描述字符串的规则或者模式,使用正则表达式可以帮助我们校验某个字符串是否符合某种特定的格式,例如邮箱的格式,就可以使用正则表达式来校验。
常用的正则符号
正则表达式平时用的并不多,但是常见的正则表达式符号还是要掌握的,以下是一些常用的正则符号:
| 字符 | 描述 | 示例 | 可匹配的字符串 |
|---|---|---|---|
| . | 除了换行符之外的任意字符 | j.va | java |
| \ | 转移字符 | \. | . |
| | | 类似于或运算,匹配左右两个表达式中的一个 | (hello|world) | hello或者world |
| () | 标记一组表达式,如果要表示( 或者 )可以使用转移字符 | (a.c) | abc |
| [] | 字符集,表示范围,里面的元素可以出个列出,也可以用范围来表示,例如[abc]或者[a-c] | a[bcd]e | abe、ace、ade |
| ^ | 匹配字符的开头,如果在[]中使用,则表示不在此范围内 | ^abc | abc |
| $ | 匹配字符的结尾 | abc$ | abc |
| \d | 匹配数字[0-9] | 1\d0 | 110 |
| \D | 匹配非数字[^\d] | a\Dc | abc |
| \s | 匹配任意空白符,包括空格、制表符、换页符等 | hello\sworld | hello world |
| \S | 匹配任意非空白符 | a\Sc | abc |
| \w | 匹配任意字母、数字、下划线。等价于 [A-Za-z0-9_] | hell\w | hello |
| \W | 匹配非字母、数字、下划线。等价于 [^A-Za-z0-9_] | hello\Wworld | hello world |
| ? | 匹配前面的表达式0次或1次 | abc? | ab、abc |
| * | 匹配前面的表达式0次或多次 | abc* | ab、abccccc |
| + | 匹配前面的表达式1次或多次 | abc+ | abc、abccccc |
| {n} | 匹配前一个字符或者表达式n次,n非负数 | hel{2}o | hello |
| {n,} | 至少匹配前一个字符或者表达式n次,n非负数 | hel{2,}o | hello、helllllo |
| {m,n} | 至少匹配m次,之多匹配n次,m、n均为非负数 | hel{2,3}o | hello、helllo |
| \A | 仅匹配开头字符 | \Aabc | abc |
| \z | 仅匹配结尾字符 | abc\z | abc |
| \b | 匹配单词的边界 | \bjava\b | java |
| \B | 匹配非单词边界 | a\Bbc | abc |
以上只是一部分常用的正则字符,还有一些其他的正则字符可以参考:
http://www.runoob.com/regexp/regexp-metachar.html
http://tool.oschina.net/uploads/apidocs/jquery/regexp.html
https://c.runoob.com/front-end/854
关于贪婪与非贪婪
贪婪模式: 在确保表达式能够匹配成功的情况下,尽可能多地匹配,默认情况下是贪婪模式。
从字面上来看好像不太容易理解,我们可以用个例子来说明,比如说我想要匹配”helloworld”这个字符串,为了说明问题,我把正则写成下面这样:
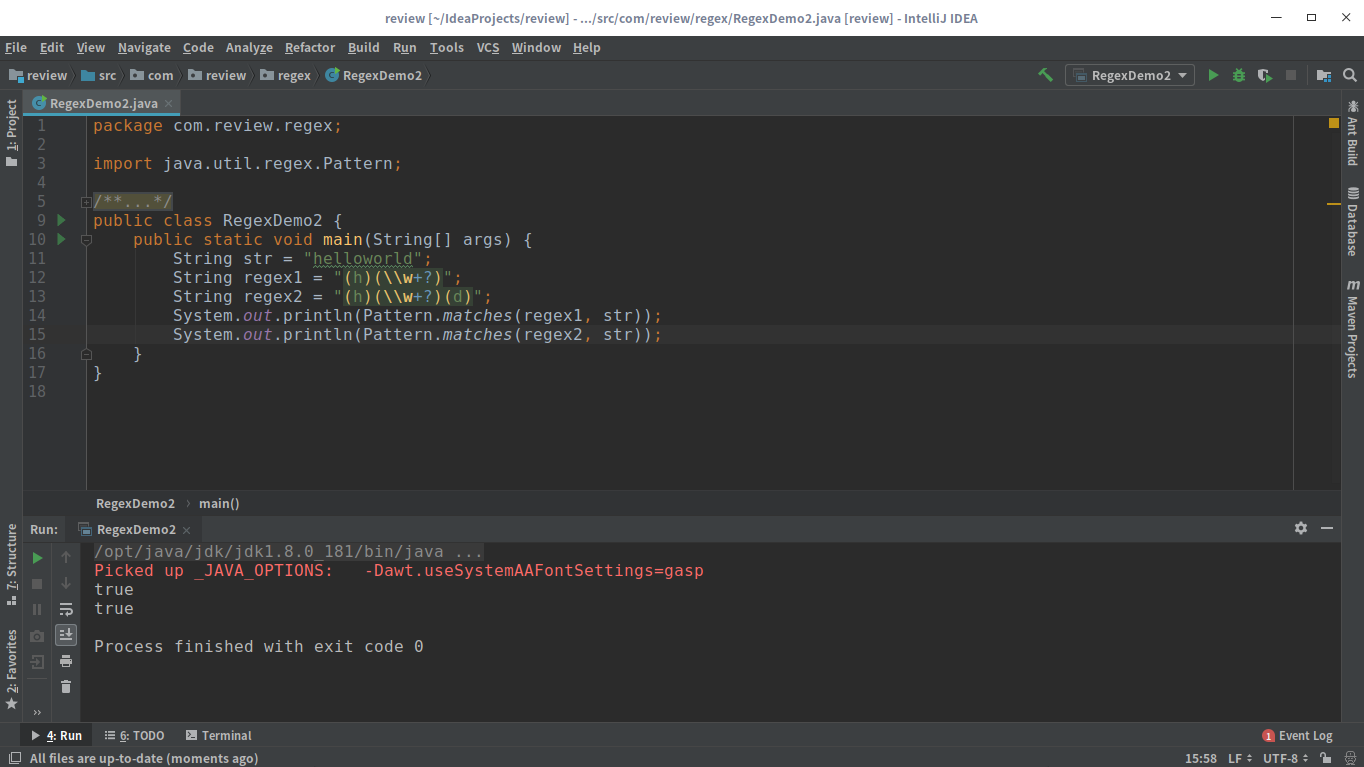
1 | + (h)(\w+) |
对于(h)(\w+)这个正则,会先匹配h然后\w+会匹配剩下的字符串”elloworld”;而(h)(\w+)(d)这个正则,也是先匹配h,\w+理论上可以匹配剩下的字符串,但是由于正则后面还有一个(d)表达式,所以为了确保能够匹配成功,\w+匹配的实际上是”elloworl”,(d)会匹配剩下的字符”d”。我们写个程序简单地验证一下,如下图:
非贪婪模式: 非贪婪模式也叫勉强模式,是指在确保表达式能够匹配成功的情况下,尽可能少地匹配。当?出现在一些限定符或者说量词(? * + {n} {n,} {m,n})的后面时,匹配的模式就是非贪婪模式。
还是以”helloworld”这个字符串为例,稍微修改一下正则:
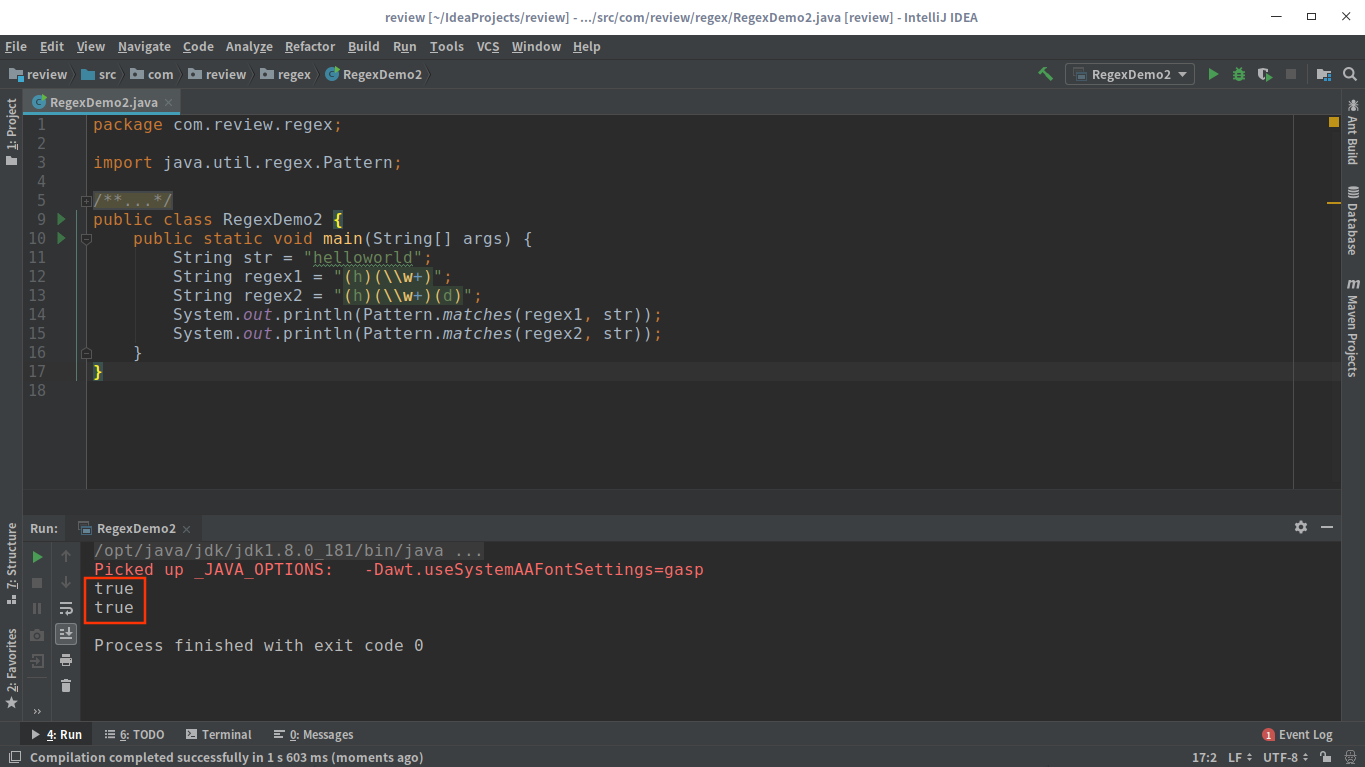
1 | + (h)(\w+?) |
对于(h)(\w+?)这个正则,会先匹配h,而(\w+?)这个表达式会尽可能少地匹配”h”之后的字符,所以它匹配的是”e”,但是通过程序验证可以发现,这个正则也是可以匹配”helloworld”这个字符串的,为什么?因为当整个表达式不成功时,非贪婪模式会最小限度地继续匹配。而另一个正则(h)(\w+?)(d)与前者有一点不太一样的地方就是,多了一个(d)表达式,所以(\w+?)需要匹配”elloworl”才能确保匹配成功。